Transpose rows to columns using Talend Open Studio
Make data easy with Helical Insight.
Helical Insight is the world’s best open source business intelligence tool.
To transpose rows to columns using Talend open studio could be a very challenging task which is required during data migration activities from flat files to other flat files. Major challenge in migrating this data to database table is that, the user is not aware of how many columns are going to be transposed in a row. So, it is not possible to have a metadata of the columns. In this case, it is always suggested to keep all the transposed column data into the single column separated by specific field separator. I have encountered multiple projects in which this task is required and due to this transpose activity, customer is not able to process and analyze the data from the source files. Many times if the data is not represented in the required format, data becomes meaningless.
Sample Data
In the data given below, it is expected to pivot column Week from rows to columns. Following data is the number of vehicles sold by particular user in a week for two different user accounts.
Account;Week;Sale
334234;Week_1;23;
334234;Week_2;72
334234;Week_3;14
116675;Week_1;33
116675;Week_3;78
Expected output
Based on above data it is expected that the data is distributed like sale for each week for respective Account.
Account;Week_1;Week_2;Week_3
334234;23;72;14
116675;33;;78
Way out – Talend Job
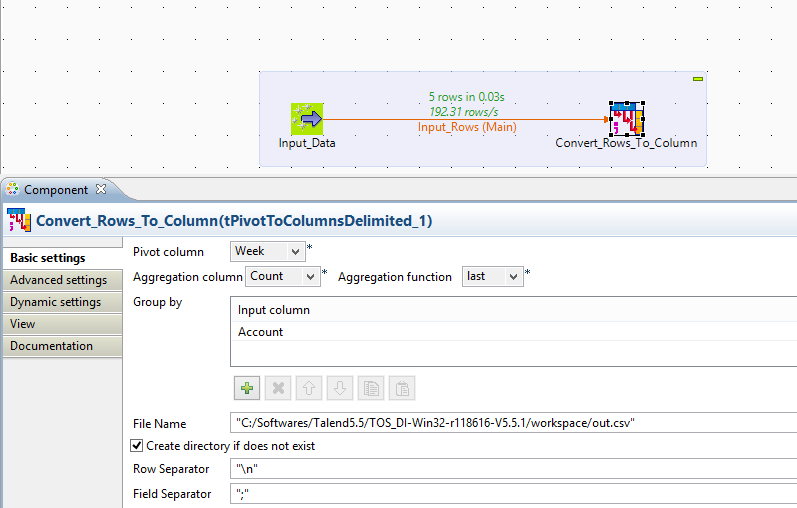
Talend Open Studio for data integration can help you to read the data from the file and convert it to column data for particular key. Talend consists of a component tPivotToColumnsDelimited. This component can convert rows to columns based on the three different conditions.
1) Pivot Column – In order to convert rows to columns, we need to identify a one column which need to be converted to multiple columns based on Aggregate column. In above case, Week is the Pivot Column.
2) Aggregate column – Aggregation column is the column from source data on which aggregation is to be applied with specific function. In above case, Sale is the Aggregate Column.
3)Aggregation function – which type of aggregation is to be applied on input data. If no aggregation function is applied, then you can select “First”. Aggregation functions available are Sum, Count, Min, Max, First, Last. In above case, First is the Aggregate function.
4) Group by – You need to provide a group by column name, this is the column based on which pivot columns are created. In above case, Account is the group by Column.
Make data easy with Helical Insight.
Helical Insight is the world’s best open source business intelligence tool.
Once you execute the job, the pivoted data is written into a flat file at the given location with specific file name. You can change this path to dynamic path using context variables and time stamp in the file name for the file. This file uses specific field separator and row separator. You can customize it depending on your need. If you want to create directory, if it does not exists, then enable the check box to create it when executed. In advance properties, you can configure CSV options to include field enclosure, advance separator for numbers and even check box for not to create a blank file when there is no data.
Converting rows to columns
Output Data
Make data easy with Helical Insight.
Helical Insight is the world’s best open source business intelligence tool.
Following table shows the data in table format which is converted from input.
| Account | Week_1 | Week_2 | Week_3 |
| 334234 | 23 | 72 | 14 |
| 116675 | 33 | 78 |
Following is the data from output file generated by the component.
Account;Week_1;Week_2;Week_3
334234;23;72;14
116675;33;;78
Above data shows null value if there is no sale by particular account in respective week. If you want to further process this file, then you can read the file and create a metadata and do further analysis of Sale by particular account holder.
Vaibhav Waghmare

Best Open Source Business Intelligence Software Helical Insight is Here